Cross-posted. This article’s canonical home is Data Lakehouse Hub.
Building the Brain of the Agentic Lakehouse: Designing an Open Catalog Architecture
An AI agent connected to a data platform needs to know three things before it can answer questions reliably: what data exists, what it means, and who is allowed to see it. In an agentic lakehouse, the catalog provides all three. Without a well-designed catalog, the agent is navigating blind.
This post covers the architectural components of an open catalog designed for AI agent access, how Apache Polaris implements the open standard, and how Dremio’s Open Catalog extends that foundation with the federation and governance features that production agentic systems require.
What the Catalog Does
The catalog’s primary job in any data lakehouse is table discovery: it tracks which tables exist, where their metadata files live, and what their schemas are. This is the function that Apache Polaris implements through the Iceberg REST catalog specification.
But for agentic analytics, table discovery is only the foundation. The catalog also needs to provide:
Business context: Not just “this table has 12 columns of these types” but “this table contains daily order aggregates, updated at 2 AM UTC, authoritative source is the order management system, relevant for revenue and fulfillment analytics.”
Semantic relationships: Which tables should be joined for certain types of questions? Which virtual dataset contains the canonical “active customer” definition? What is the relationship between the orders table and the customers table?
Access policies: Which roles can see which tables, which columns get masked for which roles, which rows are filtered based on user context?
Lineage: Where did this data come from? Which pipelines produce it? Which downstream views and reports depend on it?
A catalog that provides all four types of information gives AI agents the context they need to generate accurate, governed queries. Most standard Iceberg REST catalogs provide only table discovery. The agentic lakehouse requires all four.
Apache Polaris: The Open Standard Catalog
Apache Polaris is an open-source implementation of the Iceberg REST catalog specification, incubating in the Apache Software Foundation. It provides the standardized interface that Iceberg-compatible engines use to discover tables and get storage credentials.
The key features Polaris provides:
RBAC with credential vending: Service principals (engines, users, agents) authenticate to Polaris and receive scoped, short-lived credentials that allow access to specific table paths. An agent with a read-only role gets credentials that cover only the files in the tables it’s authorized to access.
Namespace management: Catalogs are organized into namespaces that map to your organizational structure. A namespace might represent a business domain (e.g., finance, operations, customer_success) or a data tier (bronze, silver, gold).
Multi-engine interoperability: Because Polaris follows the open REST spec, any Iceberg-compatible engine can connect. Spark, Trino, Flink, and Dremio all speak the same catalog protocol.
What Polaris doesn’t provide natively: business context (wikis and documentation), row-level security, column masking, or federation to non-Iceberg sources. These require additional layers.
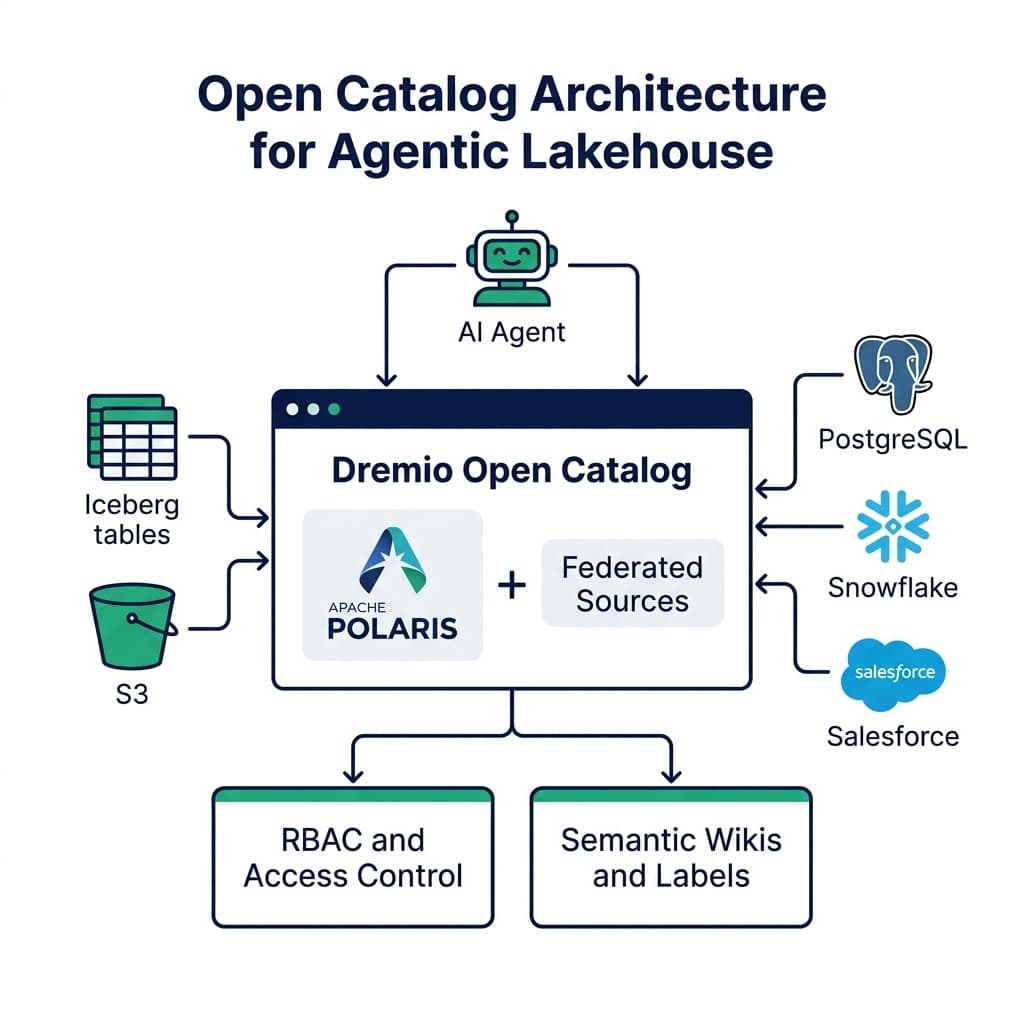
Dremio’s Open Catalog: Polaris Plus
Dremio’s Open Catalog extends Apache Polaris in two important directions.
Federated sources: Dremio’s Open Catalog formula is: Open Catalog = 1 Apache Polaris Catalog + Dremio Federated Sources. A single Dremio catalog namespace can include Iceberg tables in S3, PostgreSQL schemas, Snowflake warehouses, MongoDB collections, and Kafka streams. All of these appear in the same unified namespace, accessible through the same SQL interface.
For AI agents, this means the catalog is the single authoritative source of what data exists. The agent doesn’t need to know whether “active_customers” is stored in Iceberg or PostgreSQL : it queries the catalog, which routes the query appropriately.
Semantic layer: Every table in Dremio’s Open Catalog can have wiki documentation, column labels, and linked virtual datasets. The AI agent can query the semantic layer directly: “What does this column mean? What business metric does this table support? Is this the authoritative source?”
Dremio’s AI metadata generation creates initial wiki drafts automatically by sampling table schemas and data. A data steward reviews and approves. The catalog becomes self-documenting over time, with human oversight ensuring accuracy.
Catalog-as-Agent-Context
In a well-designed agentic lakehouse, the catalog doesn’t just store metadata : it actively serves context to the agent at query time.
When an agent connects through Dremio’s MCP server, it receives:
- A description of available schemas and tables, with their wiki documentation
- Column-level descriptions and data type information
- Metadata about which virtual datasets represent canonical business metrics
- Access control context that determines which tables and columns the agent can query
This catalog-as-context pattern means the agent doesn’t need to explore the schema through multiple round-trips : the relevant context is provided upfront. Investigation still happens iteratively, but the agent starts with business-relevant context rather than generic database metadata.
The quality of this context depends directly on the quality of the catalog documentation. Investing in documentation is investing in agent accuracy.
Open vs. Proprietary Catalog Design
The open catalog design (Apache Polaris + Dremio’s extensions) contrasts with proprietary catalog approaches where the catalog metadata format is owned by the vendor.
Portability: With an open catalog following the Iceberg REST spec, you can switch compute engines without migrating your catalog. Your semantic definitions, access policies, and table metadata stay in the catalog and are compatible with any new engine you add.
Multi-engine agent access: Multiple AI agents from different frameworks (LangChain, LlamaIndex, Anthropic tool use, Dremio’s built-in agent) can all connect to the same open catalog and access the same context. You don’t need to maintain separate semantic definitions per agent framework.
Auditability: Open catalog access logs can be exported to any SIEM or audit system. Proprietary catalogs may limit log access to their own tooling.
The tradeoff: building and maintaining an open catalog with rich semantic documentation requires engineering investment. A proprietary, managed catalog may have lower initial setup cost but higher long-term cost through lock-in and reduced portability.
Structuring the Catalog for Agent Use
When designing your catalog for AI agent access, organize namespaces around business domains rather than technical data layers.
catalog/
├── finance/
│ ├── bronze/ # Raw financial data
│ ├── silver/ # Cleaned, governed financial metrics
│ └── gold/ # Report-ready financial aggregates
├── operations/
│ ├── bronze/
│ ├── silver/
│ └── gold/
└── customer_success/
├── bronze/
├── silver/
└── gold/Each silver-layer virtual dataset should have a full wiki description, column-level labels, and access control policies. The agent is configured to query the silver layer by default, escalating to gold for specific reporting use cases.
Limit the agent’s table access to the tier appropriate for its role. An agent serving business stakeholder questions should query silver and gold, not bronze. An agent running data quality checks may need bronze access.
The catalog namespace structure directly affects the agent’s ability to navigate to the right data. Clear, consistent naming within each domain reduces exploration cost and reduces the probability of the agent selecting the wrong table.
Try Dremio Cloud free for 30 days to build and explore your open catalog architecture.