Cross-posted. This article’s canonical home is Data Lakehouse Hub.
Legacy Warehouses to Open Lakehouses: A Step-by-Step Migration Playbook
Most teams that start a warehouse-to-lakehouse migration underestimate one thing: the actual problem is trust, not technology. Your stakeholders have dashboards that have been running the same numbers for years. The moment those numbers change : even correctly , you’ve got a political problem.
The technical migration is solvable. The trust migration is harder. This playbook handles both.
Why Teams Migrate Now
The economics of staying on a proprietary warehouse have shifted. Storage costs in legacy warehouses run 3–5x what the same data costs on object storage with Iceberg. Compute can’t scale independently when it’s bundled with storage. SQL on Iceberg has reached performance parity with managed warehouses for most analytical workloads, especially with a query engine like Dremio that adds Reflections-based acceleration.
The second driver is AI. Teams building agentic analytics need open catalogs with semantic metadata. Proprietary warehouses have governance models designed for human analysts : schema-level permissions, not the column-level masking and contextual documentation that AI agents need to generate accurate SQL.
The migration isn’t about abandoning what works. It’s about building a foundation that doesn’t trap you in one vendor’s pricing model.
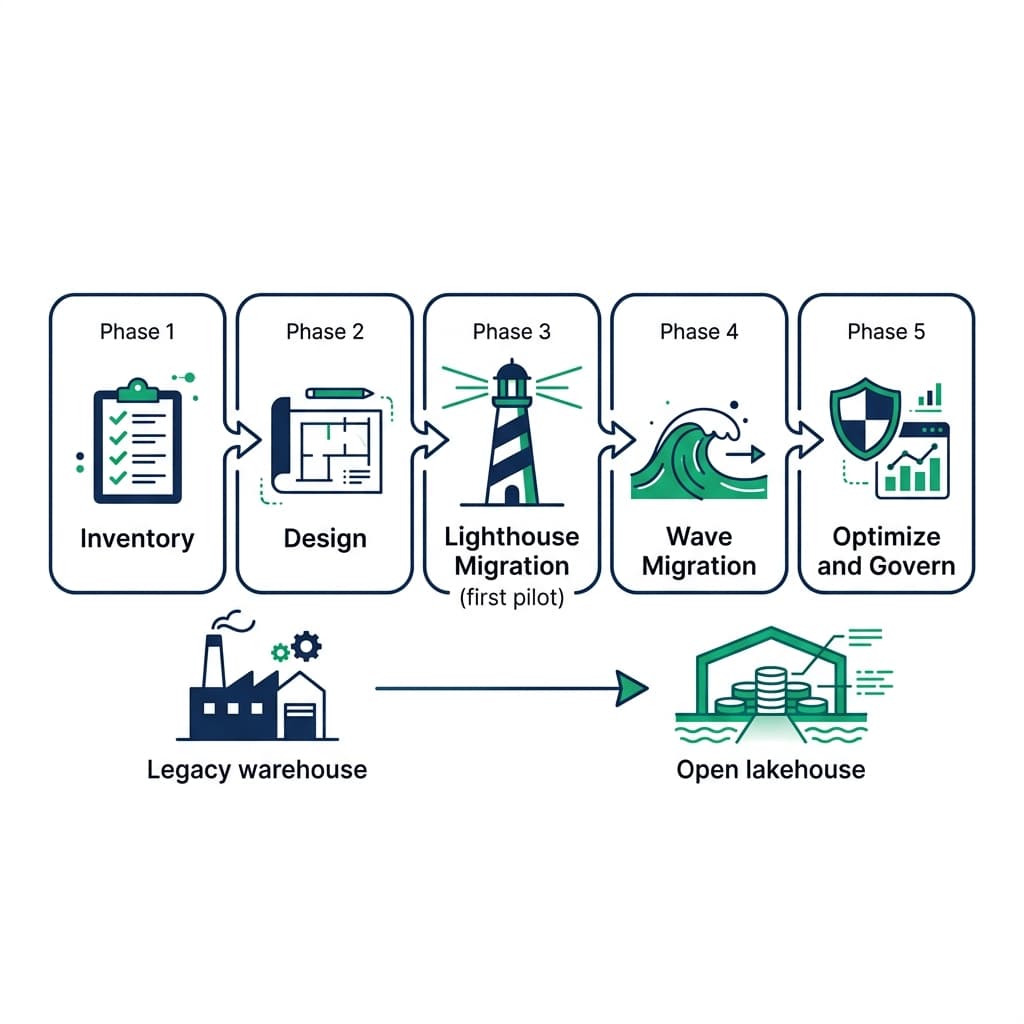
Phase 1: Inventory Everything
Before moving anything, document what you have.
Catalog every table, view, stored procedure, and ETL job in your current warehouse. For each, record:
- Row count and data volume
- Write frequency (real-time, hourly batch, daily batch)
- Query frequency and peak concurrent users
- BI tools that depend on it
- Data owners and compliance classifications (PII, regulated, etc.)
This inventory has two purposes. First, it tells you the scope of the migration. Second, it tells you the order in which to migrate : starting with high-value, lower-risk tables rather than the mission-critical ones that business stakeholders watch daily.
Sort your inventory into three categories:
- Migrate first: High query volume, non-sensitive, well-documented
- Migrate second: Important but complex, either high sensitivity or complex dependencies
- Migrate last or keep: Mission-critical financial or compliance reporting where rollback risk is highest
Phase 2: Design the Lakehouse Architecture
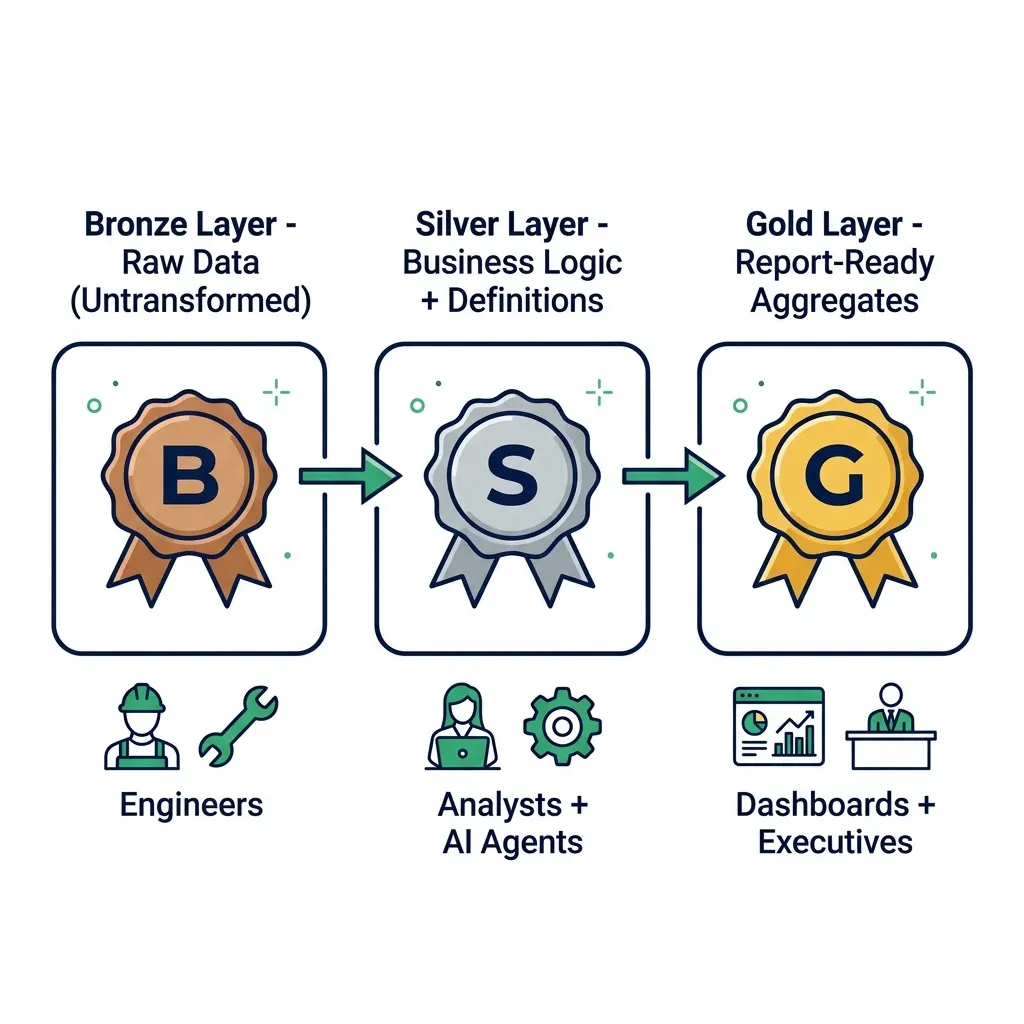
Map your current tables to a Medallion architecture before writing any migration code.
Bronze layer: Raw, typed views mapping directly to source system data. Minimal transformation. One-to-one with source tables.
Silver layer: Joins, business logic, and filter conditions. This is where “active customer” and “churn rate” get their canonical definitions.
Gold layer: Aggregated, application-specific views for specific users, teams, or AI use cases.
The Medallion mapping forces you to decide where transformations live. In a legacy warehouse, business logic accumulates in stored procedures, views, and ETL code spread across systems. The migration is your opportunity to consolidate it in the silver layer as SQL-defined virtual datasets.
Dremio’s semantic layer handles this: virtual datasets are SQL views defined in the platform, versioned, and documented with wikis. Every downstream tool : dashboards, notebooks, AI agents , reads from the same logical definitions.
Phase 3: Run a Lighthouse Migration
Pick one dataset from your “migrate first” category and run the full migration as a proof of concept.
Set up your Iceberg catalog (Apache Polaris or Dremio’s Open Catalog). Create the target Iceberg table schema. Run the initial load : either through Spark, Dremio’s ingestion tools, or your ETL framework of choice. Then run both the legacy warehouse and the new lakehouse in parallel for at least two weeks.
During the parallel run:
- Compare query outputs between the two systems for every report that uses this dataset
- Document any discrepancies and trace them to root causes
- Measure query performance in the new system against baseline
- Confirm that all connected BI tools work against the new data source
The parallel run is where trust gets built. When your finance team sees the same number in both systems for 14 consecutive days, they’ll accept the cutover.
Phase 4: Migrate in Waves
After the lighthouse migration validates the pattern, apply it in waves across the rest of your inventory.
Wave 1 covers your “migrate first” category. These go through the same parallel run process, but the pattern is now established and the team moves faster.
Wave 2 covers complex tables. These often require schema refactoring : long-accumulated technical debt that doesn’t survive the migration unchanged. Plan for extra time on schema cleanup and downstream impact analysis.
Wave 3 covers mission-critical tables. Run these in parallel for longer : 30 days minimum. Get explicit sign-off from business stakeholders before cutover.
Don’t decommission legacy tables immediately after cutover. Keep them available (read-only) for 60 days with clear documentation that they are no longer the source of truth. This gives you a rollback path and reduces the urgency pressure on your team.
Phase 5: Optimize and Govern
Once tables are on Iceberg, set up the maintenance schedule. Compaction, snapshot expiration, and manifest rewriting need to run regularly. Dremio’s Automatic Table Optimization handles this for tables in its managed catalog.
Build your governance layer in parallel with the migration, not after it. Every migrated table should have:
- Column-level PII labels
- Access control policies by role
- Wiki documentation describing what the table contains and how it’s used
- Ownership assigned to a data domain team
The lakehouse governance model can be more complete than what you had in the legacy warehouse, because open catalog systems like Apache Polaris and Dremio’s Open Catalog support metadata that proprietary warehouses don’t : including the semantic annotations that AI agents need to generate accurate queries.
The Biggest Migration Failure Mode
The most common migration failure isn’t technical : it’s running both systems too long without a cutover date.
After 90 days of parallel running, teams start treating the legacy warehouse as the authority again because it’s “proven.” The lakehouse becomes a shadow system. Data engineers maintain both indefinitely.
Set a hard cutover date for each table during the parallel run. Build consensus with stakeholders before the run starts, not after. If the parallel run surfaces discrepancies, fix them during the run : don’t extend the timeline indefinitely.
Handling BI Tool Compatibility
Your BI tools : Tableau, Power BI, Looker , all support JDBC and ODBC connections. If your legacy warehouse exposes standard SQL, switching to Dremio as the query layer requires only a connection string change, not a report rebuild.
The exceptions: if you relied on warehouse-specific SQL functions (Snowflake’s ARRAY_CONSTRUCT, Redshift’s DATEADD, BigQuery’s DATE_DIFF), those queries need rewriting in standard SQL or Dremio equivalents. Run a SQL audit on your most frequently executed dashboard queries before migration to identify any non-standard functions early.
Dremio’s SQL reference covers the full function set. Most standard analytics functions are supported directly. For the few warehouse-specific functions that don’t have direct equivalents, virtual datasets let you implement them as SQL-defined macros that your BI tools call without modification.
The good news: most Tableau and Power BI reports that use standard GROUP BY, JOIN, and aggregate functions work against Dremio unchanged. Your dashboard team won’t notice the query engine changed : they’ll just notice that their dashboards run faster.
Migrating Incremental Loads and Streaming Sources
Historical data is the easy part. Ongoing incremental loads are where migrations get complicated.
Your legacy warehouse likely has ETL jobs that run on a schedule : nightly batch loads, hourly Kafka consumers, real-time CDC pipelines. Each of these needs a new destination configured before you cut over, and tested in parallel before you rely on it.
For batch ETL, most frameworks (dbt, Airflow, Spark, Fivetran) support Iceberg as a write target. Swap the target from your legacy warehouse’s connector to the Iceberg catalog connector and test the output against the legacy tables during your parallel run.
For streaming sources, Apache Iceberg supports streaming writes through Flink and Spark Structured Streaming. The write semantics are different from traditional UPSERT : Iceberg uses append-by-default with merge-on-read for update scenarios. Verify that your streaming source’s at-least-once delivery model interacts correctly with Iceberg’s deduplication patterns before cutover.
Try Dremio Cloud free for 30 days and run your first lighthouse migration against a production-grade open lakehouse.